n8n Slack 通知模板拆解:監控事件自動推播的標準結構
拆解一個 n8n Slack 通知模板,從事件觸發、條件過濾、訊息格式化到去重防轟炸逐節點解析,看懂監控事件自動推播該有的標準結構,避免做出一個會洗版的爛通知。
Slack 通知是 n8n 最多人做的第一個自動化:哪裡有事,自動推一則訊息到頻道。聽起來很簡單,接個 Slack 節點就好。但真正上線後你會發現,一個沒設計好的通知,比沒通知還糟——半夜被無關緊要的訊息吵醒、同一件事推十次洗版、真正重要的警報反而被淹沒。
這篇我們拆一個設計合格的 Slack 通知模板,看它在「接 Slack 節點」之外多做了哪些事。這些「多做的事」,就是會洗版的爛通知跟能用的通知之間的差別。
通知模板的標準結構
先把骨架攤開。一個能上線的監控通知模板,至少有這幾段:
事件觸發 → 條件過濾 → 嚴重度判斷 → 訊息格式化
→ 去重 / 節流 → 發送 Slack → 記錄新手做的版本通常只有「事件觸發 → 發送 Slack」兩段,中間全砍掉。砍掉的那幾段,正是這篇要講的重點。
第一段:事件觸發,推什麼決定了一切
模板開頭是觸發源。Slack 通知的觸發大致分三類:
- Webhook 觸發:外部系統(監控工具、CI/CD、表單)有事就打進來
- Schedule 觸發:定時去檢查某個狀態(API 健康、資料庫筆數、額度剩餘)
- 其他 n8n workflow 觸發:當作子流程被別的流程呼叫
這裡的設計重點不是「怎麼接」,是想清楚你到底要在「什麼事件」上通知。通知的價值不在頻率,在訊號雜訊比。如果你連「什麼情況才值得吵人」都沒定義,後面做再多過濾都是補破網。
第二段:條件過濾,把雜訊擋在源頭
觸發進來後,模板第一件事是過濾,通常用 IF 或 Filter 節點。
為什麼一定要有這段?因為不是每個進來的事件都值得通知。例子:
- 監控回傳 status code,只有 5xx 才推,4xx 跟 2xx 直接丟掉
- 訂單事件進來,只有金額大於某門檻、或特定狀態才通知
- 錯誤日誌進來,只推 error 跟 fatal,info / debug 不推
把過濾放在最前面有個關鍵好處:後面的格式化、發送節點根本不會被無關事件觸發,省 API、省 quota、也讓你的 Slack 頻道乾淨。過濾擋掉的越多,留下的訊號越純。
設計原則:寧可一開始過濾得嚴一點、漏推幾則,也不要過濾太鬆把頻道變垃圾場。一旦團隊養成「這個頻道都廢話」的習慣,真正的警報就沒人看了。
第三段:嚴重度判斷,決定推到哪、吵多大

過濾完留下的事件,模板會再做一次嚴重度分級。這段常被省略,但它是通知體驗好壞的分水嶺。
同樣是要通知,severity 不同處理就該不同:
| 嚴重度 | 推到哪 | 怎麼推 |
|---|---|---|
| Critical | 警報專用頻道 + @here | 紅色、要人立刻看 |
| Warning | 一般監控頻道 | 黃色、上班時間看就好 |
| Info | 日報彙整、不即時推 | 累積後一次發 |
模板通常用一個 Switch 節點,依事件帶的等級分流到不同的發送設定。這就是為什麼有些團隊的通知讓人想關掉,有些讓人信任——差別在有沒有分級,有沒有把「critical 要立刻吵、info 不用」這件事做進流程。
第四段:訊息格式化,Block Kit 不是裝飾
接著是格式化。很多人這段就丟一段純文字,能看就好。但模板會用 Slack 的 Block Kit 結構化訊息,這不是為了好看。
結構化訊息的實際好處:
- 重點掃一眼就懂。標題粗體寫「什麼事」,欄位列出「時間、來源、影響範圍」,不用讀一整段文字。
- 附操作按鈕。可以加「查看詳情」「確認處理」的按鈕連到對應系統,從通知直接行動。
- 顏色帶嚴重度。紅黃綠的側邊條讓人不用讀字就知道急不急。
格式化節點通常用一個 Set 或 Code 節點,把事件資料組裝成 Block Kit 的 JSON。模板會把訊息樣板化:固定的版型,變動的只有填進去的值。這樣每則通知長相一致,團隊一眼就知道在看什麼。
組裝訊息:
標題:[{{severity}}] {{event_title}}
欄位:時間 / 來源 / 受影響項目
顏色:critical=danger, warning=warning
按鈕:查看詳情 → {{detail_url}}第五段:去重與節流,防止洗版的命脈
這是整個模板最能體現設計功力的一段,也是新手版本一定缺的一段。
問題是這樣的:監控系統常常在同一個故障期間,每分鐘觸發一次同樣的事件。如果你照單全推,五分鐘就是五則一模一樣的訊息洗版。真正的災難不是故障,是故障期間你的頻道被同一則訊息轟炸到沒人想看。
模板的解法有兩種,通常併用:
- 去重(dedup):用事件的指紋(來源 + 類型 + 對象)當 key,記住「最近有沒有推過同樣的」。推過就跳過。
- 節流(throttle):同一類事件,設一個冷卻時間(例如 10 分鐘內最多推一次),冷卻期內的後續事件先壓著,或累積成「這 10 分鐘發生了 N 次」一則彙整推出去。
實作上會用 n8n 的 static data 或一個外部存儲(Redis、資料庫、甚至一個 Notion 表)記錄「上次推送時間」。發送前先查、推完更新。
這段為什麼重要:通知系統的信任度是脆弱的。被洗版一次,團隊就會把頻道靜音,之後再 critical 的警報都沒人看。去重節流不是優化,是通知能不能被信任的命脈。
第六段:發送與記錄,留下軌跡
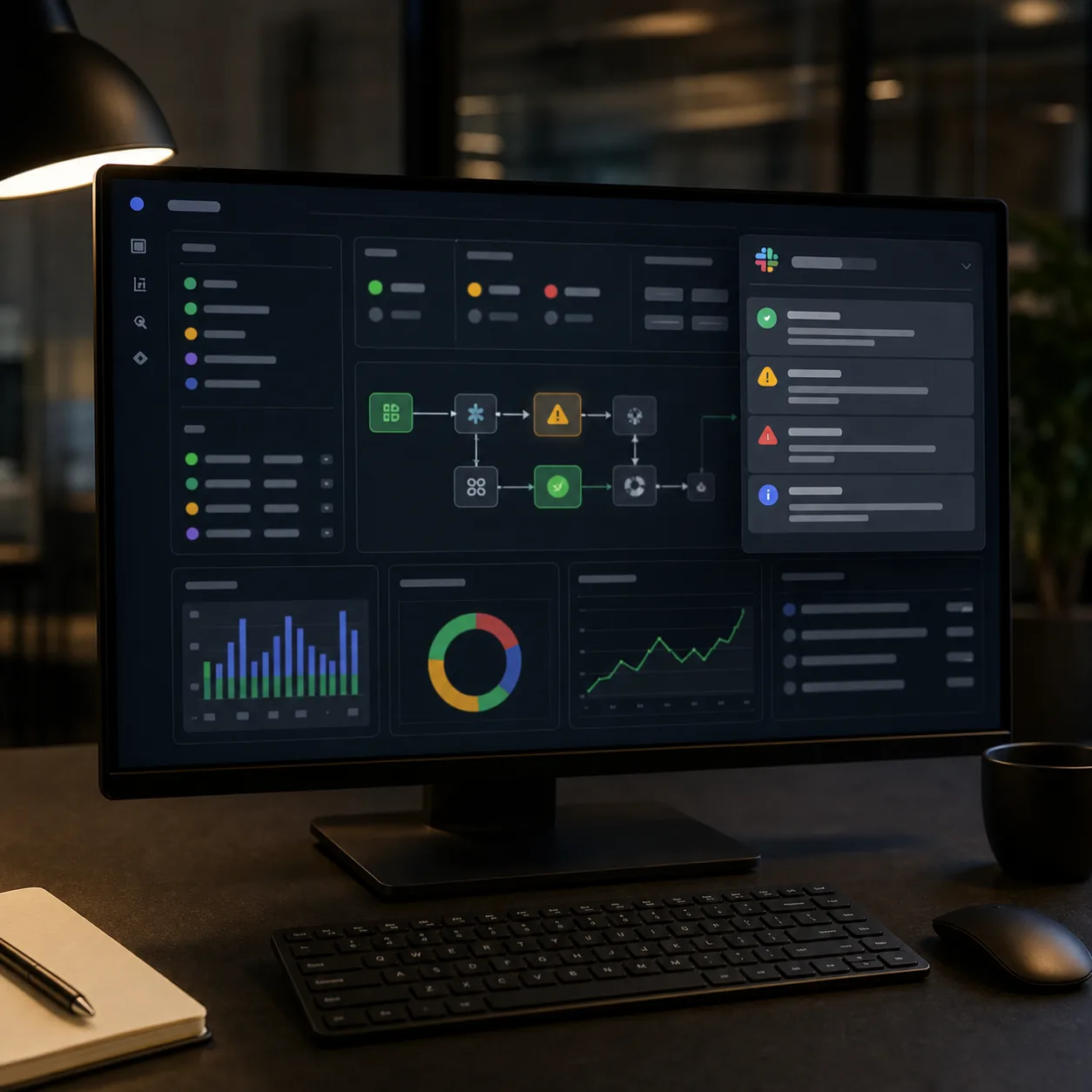
最後才是大家以為的「主角」——Slack 發送節點。經過前面五段,到這裡其實只是把組裝好的訊息送出去而已。
模板通常還會在發送後記錄一筆:什麼時候、推了什麼、推到哪。這個記錄有兩個用途:
- 給第五段的去重節流當資料來源
- 事後檢討「這次故障我們推了幾則、推得及不及時」
通知系統也需要被監控。沒有記錄,你連自己的通知有沒有正常運作都不知道。
把標準結構記下來
拆完你會發現,「接 Slack 節點」只是六段裡的第六段。一個能上線、被團隊信任的通知模板,價值全在前五段:
| 段 | 在解決什麼 |
|---|---|
| 觸發 | 在什麼事件上通知 |
| 過濾 | 哪些值得推、哪些丟掉 |
| 分級 | 多急、推到哪 |
| 格式化 | 讓人一眼看懂、能直接行動 |
| 去重節流 | 不洗版、不被靜音 |
| 發送記錄 | 送出去、留軌跡 |
下次你看到一個 Slack 通知模板,先別管它 Slack 節點怎麼設,先看它有沒有過濾、有沒有分級、有沒有去重。這三項齊全,才是個能用的通知;缺一項,上線後都會還你顏色。
自己做的時候,先做這三件事
如果你要從零做一個 Slack 通知,不用一次到位,但這三件事優先:
- 先把過濾做嚴。寧可漏推,先別洗版。
- 加一個最簡單的節流。哪怕只是「同類事件 5 分鐘內只推一次」,就能擋掉九成的轟炸。
- 訊息樣板化。固定版型,至少讓人一眼看懂是什麼事。
格式化的花俏按鈕、嚴重度多級分流,這些可以之後再加。先把「不洗版、看得懂」做到,你的通知就贏過大多數人了。
想直接拿一個已經做好過濾、分級、去重的通知模板來改,N8NMarket 有整理好的工作流模板,附節點拆解說明,照著改比自己從頭踩坑快得多。